Содержание
Главное нужно указать изображение с текстом на вашем компьютере или телефоне, обязательно выбрать основной язык текста и нажать кнопку OK внизу страницы. Остальные настройки уже выставлены по умолчанию.
Пример сфотографированного текста из книги и скриншот распознанного текста на этой фотографии:


В зависимости от размера исходного изображения и количества текста обработка может продлиться около 1 минуты. Для достижения лучшего результата распознания текста желательно обратить внимание на подсказки возле настроек. Перед обработкой изображение нужно повернуть на нормальный угол, чтобы текст шёл в правильном направлении и небыл перевёрнут вверх ногами, а также желательно обрезать лишние однотонные края без текста, если они есть. Обе OCR-программы для распознования текста отличаются друг от друга и могут давать разные результаты, что позволяет выбрать наиболее приемлемый вариант из двух.
Исходное изображение никак не изменяется, вам будет предоставлен распознанный текст в обычном текстовом документе в формате .txt с кодировкой utf-8 и после обработки его можно будет открыть прямо в окне браузера или же после скачивания – в любом текстовом редакторе.

Наверное, у каждого был случай, когда вы хотели переписать какой-то текст с картинки или PDF файла. Это могли быть какие-то документы или просто красивая цитата. У меня таких случаев было немало и меня всегда выручали сервисы распознавания текста. Конечно, существуют и программы для этой цели, но я предпочитаю такие простые задачи делать онлайн.
Ниже вы можете увидеть перечень сервисов, благодаря которым распознать текст с изображения проще простого. Все сервисы абсолютно бесплатны и не требуют регистрации.
Принцип сервисов весьма прост. Вы загружаете изображение, содержащее текст, сервис его обрабатывает и выдает вам готовый текст, избавляя вас от его переписывания. Качество распознавания текста с изображения напрямую зависит от качества самого изображения.
Где можно распознать текст с PDF файла, картинки или фотографии бесплатно
Итак, вот список сервисов:
www.newocr.com – позволяет распознать текст бесплатно с изображений таких форматов как: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сервис поддерживает множество языков. После распознания текста с картинки, его можно скопировать и вставить в свой документ.
 Как открыть файл pdf на любом устройстве – все способы и ссылки на приложения
Как открыть файл pdf на любом устройстве – все способы и ссылки на приложенияwww.onlineocr.net — аналогичный предыдущему сервис, с тем лишь отличием, что здесь распознанный текст можно скачать в форматах Microsoft Word (docx), Microsoft Exel (xlsx), Text Plain (txt).
www.free-ocr.com – сервис, поддерживающий форматы jpg, png, bmp, pdf, jpeg, tiff, tif и gif. Языков распознавания чуть меньше чем в предыдущих сервисах, но тоже немало. Скачать распознанный тест можно в txt формате.
www.i2ocr.com – сервис, поддерживающий более 60 языков. Кроме основной функции распознавания текста с изображений, здесь есть такие инструменты как:
- Конвертация web-страницы в PDF;
- Преобразование web-страницы в изображение (скриншот);
- Генератор кнопок CSS3;
- Международные клавиатуры;
- Преобразователь формата изображений;
Качество извлечения текста с изображений
Особой разницы в качестве распознавания текста на изображениях между сервисами я не заметил, поэтому в качестве примера покажу лишь первый сервис.
Для примера я взял несколько изображений разного размера и качества изображенного текста.
Изображение 1 (790 X 588 px)

Изображение 2 (793 X 1024 px)

 3 способа вытащить текст из PDF-файлов или конвертируем PDF формат
3 способа вытащить текст из PDF-файлов или конвертируем PDF форматИзображение 3 (600 X 350 px)

И вот результат самого текста, который сервис распознал на картинке.
Результат 1 изображения:
В первом изображении текст распознан идеально и вообще без ошибок.
Результат 2 изображения:
Здесь видно присутствие ошибок. Это связано с особенностю шрифта и контрастом текста на основном фоне.
Результат 3 изображения:
В третьем примере левая часть столбца имееет плохую контрастность, поэтому некоторы слова вообще не распознаны.
 7 бесплатных программ и веб-сервисов для распознавания текста
7 бесплатных программ и веб-сервисов для распознавания текстаНа основе этих трех примеров, можно сделать простой вывод – чем лучше и отчетливее виден текст на изображении, тем более качественное будет распознавание текста. Многое так же зависит от шрифта текста. Если шрифт простой, то его сервис прочтет без труда, ну а чем сложнее шрифт, тем больше будет ошибок при распознавании текста.
1. Office Lens
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в мощный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы можно редактировать в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens.







2. Adobe Scan
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Результаты удобно экспортировать в кросс-платформенный сервис Adobe Acrobat, который позволяет редактировать PDF-файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.





3. Free OCR to Word
- Распознаёт: JPG, TIF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA и другие форматы.
- Сохраняет: DOC, DOCX, TXT.
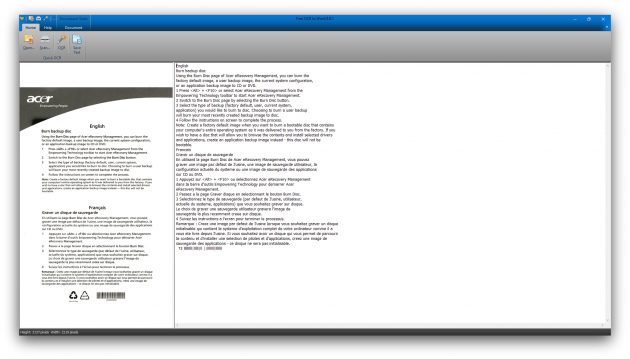
Настольная программа Free OCR to Word распознаёт выбранные пользователем изображения, извлекая из них чистый текст без форматирования. Его можно копировать в буфер обмена, сохранять в формате TXT или экспортировать в Word.
Воспользоваться Free OCR to Word →
4. FineReader Online
- Распознаёт: JPG, TIF, BMP, PNG, PCX, DCX, PDF (не защищённые паролем).
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A.
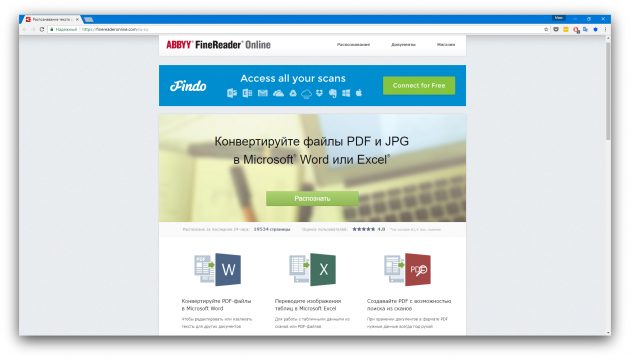
Онлайновый сервис, который конвертирует не только тексты, но и таблицы. Увы, бесплатные возможности FineReader Online ограничены. После регистрации вам позволят распознать без оплаты всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Поэтому сервис больше подойдёт тем, кто не нуждается в услугах распознавания слишком часто.
Воспользоваться FineReader Online →
5. Online OCR
- Распознаёт: JPG, BMP, TIFF, GIF, PDF.
- Сохраняет: DOCX, XLSX, TXT.
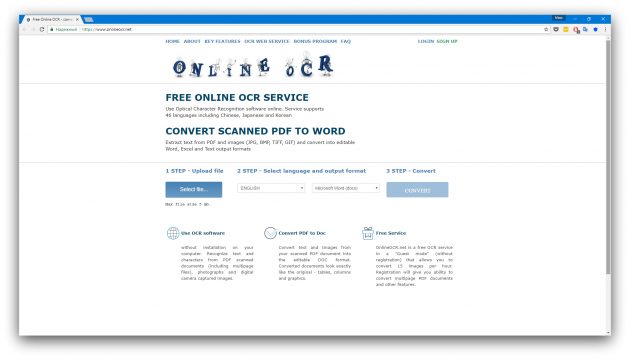
Ещё один сайт, с помощью которого можно распознать тексты и таблицы. В отличие от FineReader, в Online OCR вполне можно обойтись без регистрации. Хотя она может понадобиться, если вы планируете загружать несколько файлов для распознавания за один раз. В то же время FineReader поддерживает больше форматов.
Воспользоваться Online OCR →
6. Free OCR
- Распознаёт: JPG, GIF, TIFF BMP, PNG, PDF.
- Сохраняет: TXT.
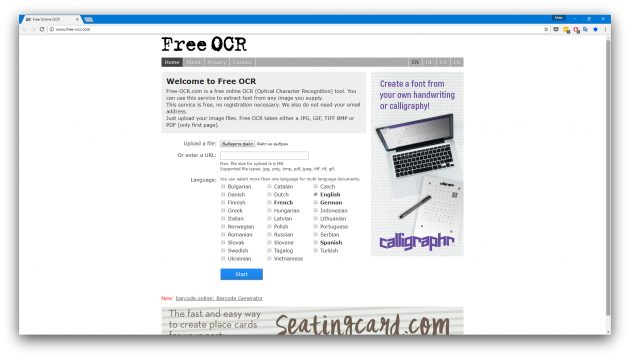
Free OCR — простейший онлайн-сервис, извлекающий текст из PDF-файлов и изображений. Результат распознавания — чистый текст без форматирования. Кроме того, сервис может уступать по точности вышеперечисленным аналогам. Зато Free OCR не требует регистрации и справляется с мультиязычными документами.
Воспользоваться Free OCR →
7. Microsoft OneNote
- Распознаёт: популярные форматы изображений.
- Сохраняет: файлы OneNote.
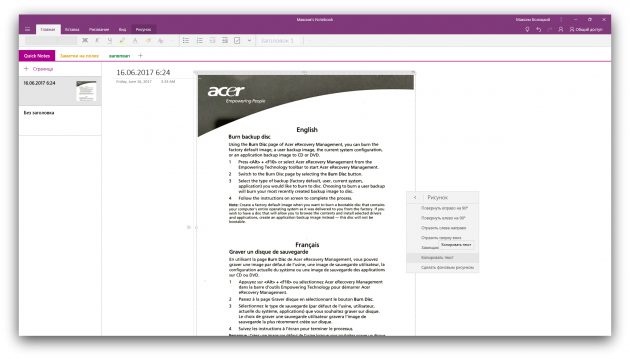
В настольной версии популярного заметочника OneNote тоже есть функция распознавания текста, которая работает с загруженными в сервис изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Рисунок» → «Текст», то всё текстовое содержимое будет скопировано в буфер обмена.

Если вы не нашли подходящей программы, взгляните на наши предыдущие подборки приложений для Android и iOS.
Используемые источники:
- https://www.imgonline.com.ua/ocr.php
- http://nazyrov.ru/raspoznavanie-teksta-onlajn-besplatno.html
- https://lifehacker.ru/raspoznavanie-teksta/

 Не открывается PDF-файл: что делать? Как открыть PDF- файл?
Не открывается PDF-файл: что делать? Как открыть PDF- файл? Как из pdf перевести текст в Word с возможностью редактирования
Как из pdf перевести текст в Word с возможностью редактирования Набор текста голосом: проверенные программы и онлайн-сервисы
Набор текста голосом: проверенные программы и онлайн-сервисы